Jean-Baptiste Le Duigou
February 21, 2022
AWS Lambda, pourquoi écrire des logs au format json ?
L’observabilité des fonctions Lambda est une nécessité pour maintenir les applications serverless en bon fonctionnement. Dans mon précédent article j’ai présenté une bonne pratique consistant à utiliser le request ID. Dans l’article d’aujourd’hui je vais parler du meilleur format à adopter pour écrire les logs, à savoir le json.
Le problème des logs non structurés
Il est parfois courant d’écrire des logs dans un format non structuré. Cela peut venir d’habitudes anciennes, d’une envie d’implémenter vite son application ou tout simplement parce que l’on y a pas réfléchi plus que cela.
Le problème est que bien souvent cela conduit à avoir différents formats au sein d’une même base de code et des déploiements associés.
Prenons par exemple ce log ci :
zap.S().Infof("Found %v transactions", len(transactions))
Nous pouvons le trouver dans Cloudwatch Logs :
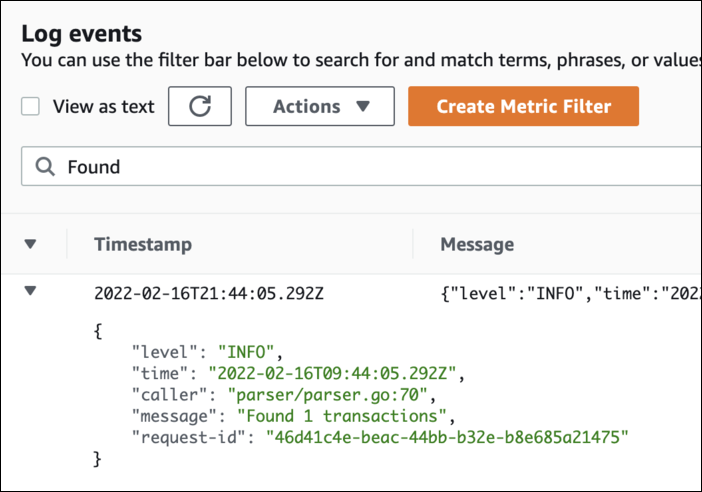
Filtrage du message dans Cloudwatch Logs
En revanche, il n’est pas possible de l’analyser ou de le transformer directement dans Cloudwatch Logs.
Il faudra pour cela passer par Cloudwatch Insights et utiliser la fonction parse.
Une requête possible pour cela serait :
fields message
| parse message "Found * transactions" as totalTx
| filter message like /Found/
| sort @timestamp desc
| limit 20
Le résultat obtenu est celui ci :
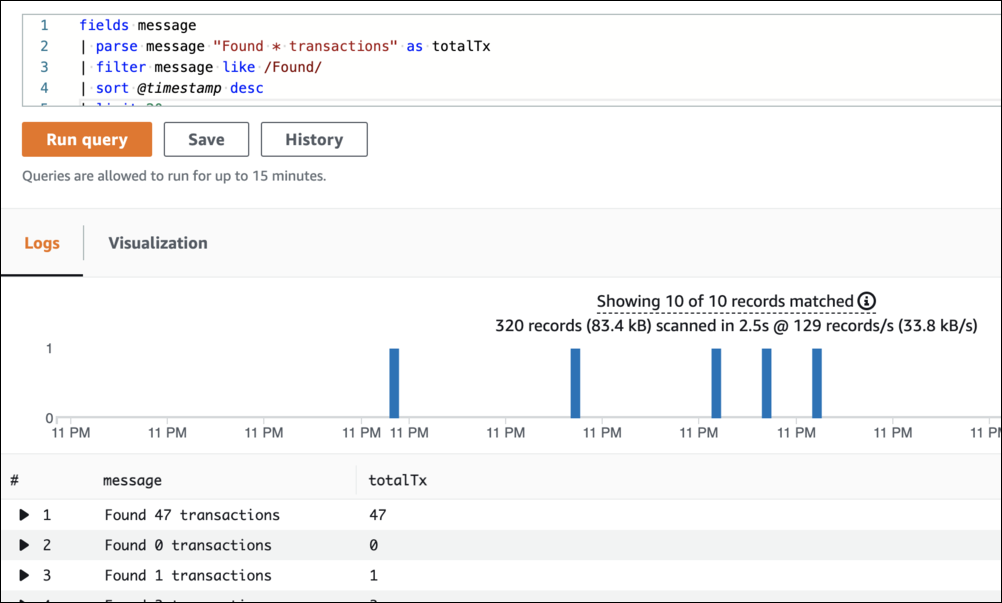
Utilisation de parse dans Cloudwatch Insights
Cela fonctionne, mais nécessite de connaître le format exact du message.
Si ce format diffère d’une fonction lambda à l’autre, cela devient un véritable casse-tête de jongler entre ces différents formats.
La puissance de Cloudwatch Logs
L’avantage d’utiliser un format JSON est que le le service Cloudwatch Logs comprend et analyse ce format. Ainsi, il découvre automatiquement les différents attributs, les parse et les rends disponible pour analyse et filtrage. Si l’on reprend l’exemple précédent et qu’on le convertit en json, on obtient maintenant ce log ci :
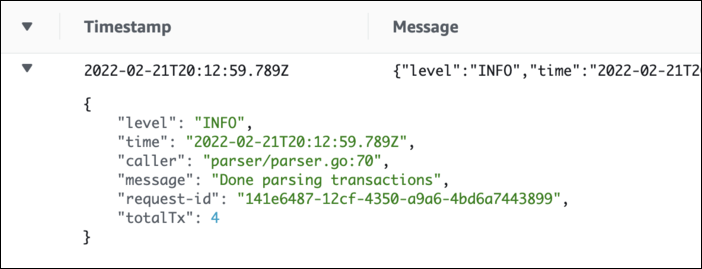
Message en json dans Cloudwatch Logs
Il est maintenant possible de filtrer directement dans Cloudwatch Logs, par exemple pour identifier les exécutions ayant plus d’une transaction.
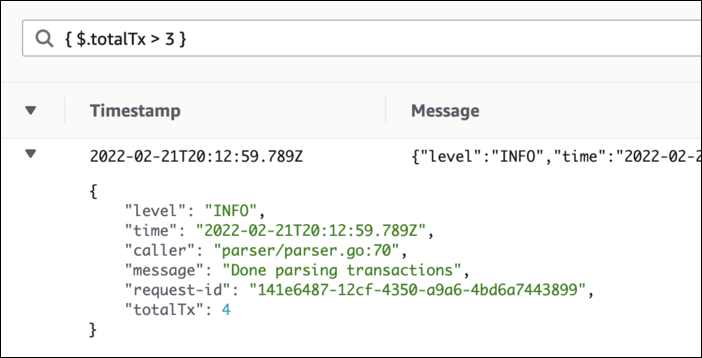
Filtrage par attribut totalTx
De même, il devient plus facile d’utiliser Cloudwatch Insights car les attributs du JSON sont directement disponibles.
Exemple concret avec zap
Comment configurer zap, mon framework de log préféré, pour utiliser le format JSON ?
La première chose à faire est de définir l’encodeur que l’on souhaite utiliser, dans notre cas json. Cela se fait à l’aide d’un objet zap.Config:
func initLogger(ctx context.Context) {
cfg := zap.Config{
Encoding: "json",
// other config parameters
}
logger, _ := cfg.Build()
zap.ReplaceGlobals(logger)
defer logger.Sync() // flushes buffer, if any
}
La deuxième étape consistera à repenser les formulations et la façon dont est appelé zap.
Par exemple au lieu de cela :
zap.S().Infof("Found %v transactions", len(transactions))
Il sera plus intéressant d’avoir ceci :
zap.L().Info("Done parsing transactions", zap.Int("totalTx", len(transactions)))
On le voit, la phrase évolue pour permettre d’extraire les attributs et de les passer en tant que Field.
Un Field dans le monde de zap est simplement une paire de clef/valeur qui permet d’ajouter du contexte lors de l’écriture d’un message dans le log.
Au passage, le fait de se passer du Sugared Logger permet de profiter des meilleures performances possibles de zap.
Si tu es arrivé jusqu’ici, merci beaucoup d’avoir lu cet article !
Pense à t’abonner à la mailing list pour ne rater aucun article, le formulaire se trouve en bas de page.
Si tu souhaites approfondir le sujet du logging des fonctions Lambda je te recommande la documentation officielle à ce sujet.
Photo de couverture par Mr Cup / Fabien Barral.